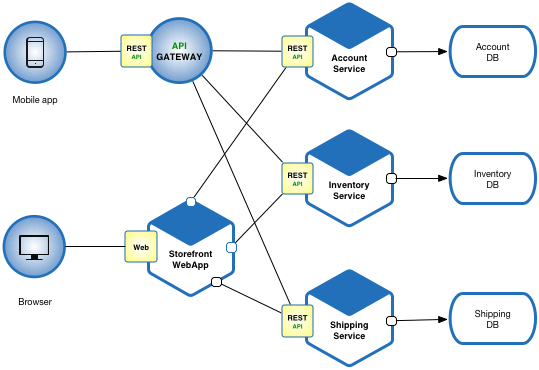
Define an architecture that structures the application as a set of loosely coupled, collaborating services. This approach corresponds to the Y-axis of the Scale Cube. Each service implements a set of narrowly read more… (more…)

Jit brings to the table over 19 years of experience in Building, Implementing and Driving Technology Solutions. From joining startups with a team of a handful to driving them up the success ladder with millions of users and building best in class international platforms, he has been there and seen it all. read more… (more…)
Define an architecture that structures the application as a set of loosely coupled, collaborating services. This approach corresponds to the Y-axis of the Scale Cube. Each service implements a set of narrowly read more… (more…)

Important for the product based organization, Software engineers should also act as Tech Support at least twice a month. read more… (more…)

What’s the difference between tags and branches? The workspace is (almost always) associated with a branch, called master by default. When it is, a commit will automatically update the master reference to point to that read more… (more…)