Define an architecture that structures the application as a set of loosely coupled, collaborating services. This approach corresponds to the Y-axis of the Scale Cube. Each service implements a set of narrowly read more… Continue Reading
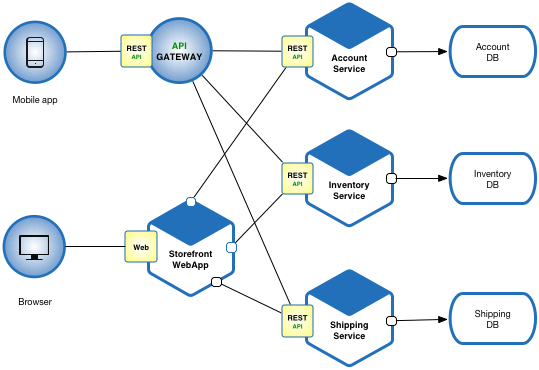
Define an architecture that structures the application as a set of loosely coupled, collaborating services. This approach corresponds to the Y-axis of the Scale Cube. Each service implements a set of narrowly read more… Continue Reading
“One thing: you have to walk, and create the way by your walking; you will not find a ready-made path. It is not so cheap, to reach to the ultimate realization of truth. Read More Continue Reading

Important for the product based organization, Software engineers should also act as Tech Support at least twice a month. read more… Continue Reading

What’s the difference between tags and branches? The workspace is (almost always) associated with a branch, called master by default. When it is, a commit will automatically update the master reference to point to that read more… Continue Reading
Brainstorming is a group or individual creativity technique by which efforts are made to find a conclusion for a specific problem by gathering a list of ideas spontaneously contributed by its member(s). The term was popularized by Alex Faickney Osborn in the 1953 book Applied Imagination. Osborn claimed that brainstorming was more effective than individuals working alone in generating ideas, although more recent research has questioned this conclusion. Today, the term is used as a catch all for all group ideation sessions.
In another words, Brainstorming with a group of people is a powerful technique. Brainstorming creates new ideas, solves problems, motivates and develops teams. Brainstorming motivates because it involves members of a team in bigger management issues, and it gets a team working together. However, brainstorming is not simply a random activity. Brainstorming needs to be structured and it follows brainstorming rules. The brainstorming process is described below, for which you will need a flip-chart or alternative. This is crucial as Brainstorming needs to involve the team, which means that everyone must be able to see what’s happening. Brainstorming places a significant burden on the facilitator to manage the process, people’s involvement and sensitivities, and then to manage the follow up actions. Use Brainstorming well and you will see excellent results in improving the organization, performance, and developing the team.
1. Lay out the problem you want to solve.
This may be easier said than done. Keeney describes a doctoral student who is at sea while trying to come up with a dissertation topic and advisor. The student grasps for ideas with only the vaguest idea of a goal, stated as negatives rather than positives. “I don’t think I could do it,” “it is not interesting to me,” “it seems too hard,” and “it would be too time consuming.” Then finally someone suggests an idea that doesn’t have any of those negatives. The doctoral student grabs the topic. But Keeney says this is a poor way to make a major decision. Instead the student should keep pushing until they come up with at least five more alternatives, and then, considering all those, “identify your objectives for your dissertation, evaluate the alternatives and select the best.” It will be well worth the effort.
2. Identify the objectives of a possible solution.
This is what Keeney did for the German energy company and what he’s done for several government agencies, including the Department of Homeland Security and the energy department. It’s not easy and it takes time but if you can approach your goals critically and hone in on what you want to achieve, your brainstorming session will be much more effective.
Keeney offers a great example of this process. David Kelley, the founder of renowned design firm IDEO, wanted to design a product that would enable cyclists to transport and drink coffee while they were riding. A couple of ways to describe what he wanted to design: “spill-proof coffee cup lids,” or “bicycle cup holders.” But a much better description is the following objective: “helping bike commuters to drink coffee without spilling it or burning their tongues.” Keeney likes this statement because it clearly lays out IDEO’s objectives, to help bike commuters 1) drink coffee, 2) avoid spills, 3) not burn their tongues. He even contributes a few objectives of his own: avoid distractions while biking, don’t contribute to accidents, keep the coffee hot and minimize costs. Going into that much detail before brainstorming about ways to design the cup holder makes IDEO much more likely to succeed.
3. Try to generate solutions individually.
Before heading into a group brainstorming session, organizations should insist that staffers first try to come up with their own solutions. One problem with group brainstorming is that when we hear someone else’s solution to a problem, we tend to see it as what Keeney calls an “anchor.” In other words, we get stuck on that objective and potential solution to the exclusion of other goals. For instance, when Keeney was consulting with a cell phone maker years ago, the company had numerous objectives. It wanted to produce a lightweight phone that also had GPS capabilities (Keeney did this consulting gig some time ago, but he insists the example remains illustrative). When company executives got together to brainstorm ideas about how to build a better phone, one person brought up the issue of weight. Suddenly everyone became fixated on that idea and forgot about their other objectives. Coming into a meeting with potential solutions reduces the risk that participants will get bogged down on one objective.
4. Once you have gotten clear on your problems, your objectives and your personal solutions to the problems, work as a group.
Though he acknowledges that it’s a challenge not to “anchor” on one solution in a brainstorming session, Keeney believes that if participants have done their homework, clarifying the problem, identifying objectives, and individually trying to come up with solutions, a brainstorming session can be extremely productive.
At the end of the paper, he describes a 2008 workshop he held to try to come up with ways to improve evacuations in large buildings in case of a terrorist attack, based on a recommendation from the National Institute of Standards and Technology. Keeney brainstormed for two-and-a-half days with 30 people with expertise in everything from firefighting and building codes to handicapped people and human behavior. The result, after going through Keeney’s four-step process: a list of 300 new alternative ways to speed evacuation. Then the participants evaluated the many ideas, which included using cell phone alarms to guide people to exits and building linked sky bridges on every fifth floor. The hope, of course, is that these solutions will never be tested. But Keeney’s brainstorming method helped the group find effective suggestions..
Few important points
Load balancers are used to increase capacity (concurrent users) and reliability of applications. They improve the overall performance of applications by decreasing the burden on servers associated with managing and maintaining application and network sessions, as well as by performing application-specific tasks.
Basically, a load balancer is a device that acts as a reverse proxy and distributes network or application traffic across a number of servers.
Load balancers are generally grouped into two categories:
1. Layer 4 and
2. Layer 7.
Layer 4 load balancers act upon data found in network and transport layer protocols (IP, TCP, FTP, UDP).
Layer 7 load balancers distribute requests based upon data found in application layer protocols such as HTTP.
Requests are received by both types of load balancers and they are distributed to a particular server based on a configured algorithm. Some industry standard algorithms are:
Layer 7 load balancers can further distribute requests based on application specific data such as HTTP headers, cookies, or data within the application message itself, such as the value of a specific parameter.
Load balancers ensure reliability and availability by monitoring the “health” of applications and only sending requests to servers and applications that can respond in a timely manner.
Ultra Monkey is a project to create load balanced and highly available network services. For example a cluster of web servers that appear as a single web server to end-users. The service may be for end-users across the world connected via the internet, or for enterprise users connected via an intranet.
More Details: http://www.ultramonkey.org/
It is a high availability cluster software implementation from Linux leader Red Hat. It provide two type services:
More Details:- http://www.redhat.com/cluster_suite/
LVS is ultimate open source Linux load sharing and balancing software. You can easily build a high-performance and highly available server for Linux using this software.
More Details:- http://www.linux-vs.org/
Linux-HA provides sophisticated high-availability (failover) capabilities on a wide range of platforms, supporting several tens of thousands of mission critical sites.
More Details: http://www.linux-ha.org/.
Basic Guideline for High Availability MySQL
We are discussing DRBD HA here. So first things to go is
Following Steps are required:
We need to reserve a huge physical volume which would be later used as a DRBD volume.
Don’t specify any file system type.
fdisk /dev/sda
Should print:
The number of cylinders for this disk is set to 9729.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
Command (m for help): p
Disk /dev/sda: 80.0 GB, 80026361856 bytes
255 heads, 63 sectors/track, 9729 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sda1 * 1 2611 20972826 83 Linux
/dev/sda2 2612 2872 2096482+ 82 Linux swap
/dev/sda3 2873 3003 1052257+ 8e Linux LVM
/dev/sda4 3004 9729 54026595 5 Extended
/dev/sda5 3004 9729 54026563+ 8e Linux LVM
We are going to use /dev/sda5 as a DRBD device.
On Server1 and Server2
yum -y install drbd
yum -y install kernel-module-drbd-2.6.9-42.ELsmp
modprobe drbd
vi /etc/drbd.conf
#
# please have a a look at the example configuration file in
# /usr/share/doc/drbd/drbd.conf
#
# Our MySQL share
resource db
{
protocol C;
incon-degr-cmd “echo ‘!DRBD! pri on incon-degr’ | wall ; sleep 60 ; halt -f”;
startup { wfc-timeout 0; degr-wfc-timeout 120; }
disk { on-io-error detach; } # or panic, …
syncer {
group 1;
rate 6M;
}
on server1 {
device /dev/drbd1;
disk /dev/sda5;
address 10.10.150.1:7789;
meta-disk internal;
}
on server2 {
device /dev/drbd1;
disk /dev/sda5;
address 10.10.150.2:7789;
meta-disk internal;
}
}
On both servers:
drbdadm adjust db
On server1:
drbdsetup /dev/drbd1 primary –do-what-I-say
service drbd start
On server2:
service drbd start
On both servers (see status):
service drbd status
On server1:
mkfs -j /dev/drbd1
tune2fs -c -1 -i 0 /dev/drbd1
mkdir /db
mount -o rw /dev/drbd1 /db
On server2:
mkdir /db
For manual switchover (This wont be needed as HA will do this for you):
umount /db
drbdadm secondary db
On secondary server
drbdadm primary db
service drbd status
mount -o rw /dev/drbd1 /db
df
This finishes DRBD part of it. You have created a DRBD mount which will be used as a data directory for your MySQL.
mkdir /db/mysql
NOTE: /db should be mounted to do this
mkdir /db/mysql/data
chown -R mysql /db/mysql/data
chgrp -R mysql /db/mysql/data
mv /home/mysql/data /db/mysql/data
ln -s /db/mysql/data /home/mysql/data
mv /home/mysql/data /tmp
ln -s /db/mysql/data /home/mysql/data
Now, start MySQL on server1. Create some sample database and table. Stop MySQL. Do a manual switchover of DRBD. Start MySQL on server2 and query for that table. It should work. But, this is of no use if you have to switchover manually every time. Now we are heading to HA.
yum -y install gnutls*
yum -y install ipvsadm*
yum -y install heartbeat*
vi /etc/sysctl.conf and set net.ipv4.ip_forward = 1
vi /etc/sysctl.conf
# Controls IP packet forwarding
net.ipv4.ip_forward = 1
/sbin/chkconfig –level 2345 heartbeat on
/sbin/chkconfig –del ldirectord
We need to setup the following conf files on both machines:
a. vi /etc/ha.d/ha.cf
#/etc/ha.d/ha.cf content
debugfile /var/log/ha-debug
logfile /var/log/ha-log
logfacility local0
keepalive 2
deadtime 30
warntime 10
initdead 120
udpport 694 #(If you have multiple HA setup in same network.. use different ports)
bcast eth0 # Linux
auto_failback on #(This will failback to server1 after it comes back)
ping 10.10.150.100 #(Your gateway IP)
apiauth ipfail gid=haclient uid=hacluster
node server1
node server2
On both machines:
b. vi /etc/ha.d/haresources
NOTE: Assuming 10.10.150.3 is virtual IP for your MySQL resource and mysqld is the LSB resource agent.
#/etc/ha.d/haresources content
server1 LVSSyncDaemonSwap::master IPaddr2::10.10.150.3/24/eth0 drbddisk::db Filesystem::/dev/drbd1::/db::ext3 mysqld
c. vi /etc/ha.d/authkeys
#/etc/ha.d/authkeys content
auth 2
2 sha1 YourSecretString
Now, make your authkeys secure:
chmod 600 /etc/ha.d/authkeys
Start:
On both machines(first on server1):
Stop MySQL.
Make sure MySQL does not start on system init.
For that:
/sbin/chkconfig –level 2345 MySQL off
/etc/init.d/heartbeat start
These commands will give you status about this LVS setup:
/etc/ha.d/resource.d/LVSSyncDaemonSwap master status
ip addr sh
/etc/init.d/heartbeat status
df
/etc/init.d/mysqld status
Access your HA-MySQL server like:
mysql -h10.10.150.3
Shutdown server1 to see MySQL up on server2.
Start server1 to see MySQL back on server1..
MySQL User Account Management:
Note: Operating system user names are completely unrelated to MySQL user names. MySQL passwords have nothing to do with passwords for logging in to your operating system.
Warning: The limit on MySQL user name length is hard-coded in the MySQL servers and clients, and trying to circumvent or avoid it by modifying the definitions of the tables in the mysql database does not work.
MySQL account information is stored in the tables of the mysql database
Creating User accounts:
We can create MySQL user accounts in 3 ways:
Note: The preferred method is to use account-creation statements because they are more concise and less error-prone than manipulating the grant tables directly.
Method 1:
CREATE USER [IDENTIFIED BY [PASSWORD] ' password'user[IDENTIFIED BY [PASSWORD] ']]...
The CREATE USER statement was added in MySQL 5.0.2. This statement creates new MySQL accounts. To use it, you must have the global CREATE USER privilege or the INSERT privilege for the mysql database. For each account, CREATE USER creates a new record in the mysql.user table that has no privileges. An error occurs if the account already exists.
Example:
mysql> create user ‘monitor’; mysql> SET PASSWORD for ‘monitor’ = PASSWORD(‘monitor123’); mysql> flush privileges;
Altering a user:
mysql> update mysql.user set password=password('monitor123') where user='monitor' and host='localhost';
or
mysql> flush privileges;
Delete a user: To use it, you must have the global CREATE USER privilege or the DELETE privilege for the mysql database.
mysql> delete from mysql.user where user = 'monitor'; or mysql> flush privileges;
Drop a user: The DROP USER statement removes one or more MySQL accounts. To use it, you must have the global CREATE USER privilege or the DELETE privilege for the mysql database.
DROP USER user [, user]...
DROP USER monitor;
The statement removes privilege rows for the account from all grant tables.
To remove a MySQL account completely (including all of its privileges), we should use the following procedure.
– Use SHOW GRANTS to determine what privileges the account has.
– Use REVOKE to revoke the privileges displayed by SHOW GRANTS .
– This removes rows for the account from all the grant tables except the user table, and revokes any global privileges listed in the user tables.
– Delete the account by using DROP USER to remove the user table row.
Note: DROP USER does not automatically close any open user sessions. Rather, in the event that a user with an open session is dropped, the statement does not take effect until that user’s session is closed. Once the session is closed, the user is dropped, and that user’s next attempt to log in will fail.
DROP USER does not automatically delete or invalidate any database objects that the user created. This applies to tables, views, stored routines, and triggers.
Method 2: We can create the user with the command GRANT statement.
Syntax for the Grant statement:
http://dev.mysql.com/doc/refman/5.1/en/grant.html
The GRANT statement enables system administrators to create MySQL user accounts
and to grant rights to accounts. To use GRANT, you must have the GRANT OPTION
privilege, and you must have the privileges that you are granting.
Example: GRANT ALL ON *.* TO ‘monitor’@’localhost’ identified by ‘monitor123’;
By using GRANT statement, at a time we can create user , and can grant privileges
And can set the password to that particular account.
We can grant GLOBAL Privileges, DATABASE Privileges, TABLE privileges, COLUMN
privileges.
Assigning Account Passwords:
To assign a password when you create a new account with CREATE USER, include an IDENTIFIED BY clause:
mysql > CREATE USER ‘username’@’localhost’ IDENTIFIED by ‘password’;
To assign or change a password for an existing account, one way is to issue a SET PASSWORD statement:
Guidelines for Password Security:
-MySQL stores passwords for user accounts in the mysql.user table. Access to this
table should never grant privileges to any other non-administrative accounts.
– Passwords can appear as plain text in SQL statements such as CREATE USER,
GRANT, and SET PASSWORD. To guard against unwarranted exposure to log files, they should be located in a directory that restricts access to only the server and the database administrator.
– Replication slaves store the password for the replication master in the master.info file. Access to this file should be restricted to the database adminstrator.
– Database backups that include tables or log files containing passwords should be protected using a restricted access mode..
The BLACKHOLE storage engine acts as a “black hole” that accepts data but throws it away and does not store it. Retrievals always return an empty result:
mysql> CREATE TABLE test(i INT, c CHAR(10)) ENGINE = BLACKHOLE;
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO test VALUES(1,’record one’),(2,’record two’);
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM test;
Empty set (0.00 sec).